In Kubernetes, a pod is the littlest API object, or in additional specialized terms, it’s the atomic booking unit of Restart Kubernetes POD. In a group, a pod addresses a running application process. It holds at least one compartments alongside the assets shared by every holder, like storage and organization.
Kubernetes Pods ought to work without intercession however once in a while you could hit an issue where a compartment’s not working the manner in which it ought to. Restarting the Pod can assist with restoring tasks to typical.
Kubectl doesn’t have an immediate approach to restarting individual Pods. Pods are intended to remain running until they’re supplanted as a feature of your organization schedule. This is normally when you discharge another rendition of your compartment picture.
The following are a couple of strategies you can utilize when you need to restart Pods without building another picture or running your CI pipeline. They can help when you figure a new arrangement of compartments will get your responsibility running in the future.
Restart Kubernetes POD is an open-source holder coordination framework for automating arrangement, scaling and the board of containerized applications. This article exhibits how to restart your running pods with kubectl (an order line interface for running orders against Kubernetes groups).
Kubernetes is an open-source framework worked for organizing, scaling, and sending containerized Restart Elusive Target Hitman 3. In the event that you’ve invested any energy working with Kubernetes, you know how valuable it is for overseeing compartments.
Why You Might Want to Restart a Pod
To start with, we should discuss a few reasons you could restart your pods:
- Asset use isn’t expressed or when the product acts in an unexpected manner. On the off chance that a holder with 600 Mi of memory endeavors to designate extra memory, the pod will be ended with an OOM. You should restart your pod in this present circumstance subsequent to changing asset particulars.
- A pod is caught in an ending state. This is found by searching for pods that have had their holders ended at this point the pod is all actually working. This generally happens when a bunch hub is removed from administration startlingly, and the group scheduler and regulator supervisor can’t tidy up every one of the pods on that hub.
- A mistake can’t be fixed.
- Breaks.
- Mixed up arrangements.
- Mentioning constant volumes that are not accessible.
Restarting Kubernetes Pods
Suppose one of the pods in your holder is detailing a mistake. Contingent upon the restart strategy, Restart Kubernetes POD could attempt to automatically restart the pod to get it working once more. However, that doesn’t necessarily in all cases fix the issue.
In the event that Kubernetes can’t fix the issue all alone, and you can’t track down the wellspring of the mistake, restarting the pod is the quickest method for getting your application working once more.
Technique 1: Rolling Restart
As of update 1.15, Kubernetes allows you to do a rolling restart of your organization. As another expansion to Kubernetes, this is the quickest restart technique.
- kubectl rollout restart arrangement [deployment_name]
The previously mentioned order plays out a step-by-step closure and restarts every holder in your organization. Your application will in any case be accessible as the vast majority of the holders will in any case be running.
Technique 2: Using Environment Variables
Another technique is to set or change a climate variable to Restart Kubernetes POD to restart and match up with the progressions you made.
For example, you can change the compartment sending date:
- kubectl set env sending [deployment_name] DEPLOY_DATE=”$(date)”
In the model over, the order set env sets up an adjustment of climate factors, sending [deployment_name] chooses your organization, and DEPLOY_DATE=”$(date)” changes the sending date and powers the pod restart.
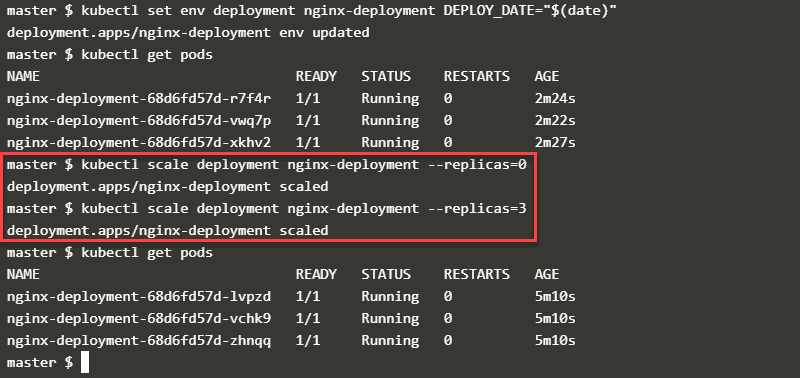
Strategy 3: Scaling the Number of Replicas
At last, you can utilize the scale order to change what number copies of the failing pod there are. Setting this add up to zero basically switches the pod off:
- kubectl scale organization [deployment_name] – – replicas=0
To restart the pod, utilize a similar order to set the quantity of copies to any esteem bigger than nothing:
- kubectl scale arrangement [deployment_name] – – replicas=1
At the point when you set the quantity of reproductions to nothing, Kubernetes annihilates the copies it never again needs.
When you set a number higher than nothing, Restart Kubernetes POD makes new reproductions. The new imitations will have unexpected names in comparison to the old ones. You can utilize the order kubectl get pods to actually look at the situation with the pods and see what the new names are.
Conclusion
Restart Kubernetes POD is a very valuable framework, yet like some other framework, it isn’t sans shortcoming.
At the point when issues do happen, you can utilize the three strategies recorded above to rapidly and securely get your application working without closing down the help for your customers.
Subsequent to restarting the pods, you have opportunity and energy to find and fix the genuine reason for the issue.